Vi presentiamo DigiGlot, una newsletter sulle lingue e la tecnologia



Elmo Bautista e il suo defunto padre Espíritu Bautista registrano digitalmente parole nella lingua Yanesha del Perù, durante un seminario organizzato dal Living Tongues Institute (Istituto delle Lingue Viventi). Foto di Eddie Avila, riprodotta con permesso.
Benvenuti alla edizione inaugurale di DigiGlot, una newsletter collaborativa bisettimanale che riporta come le comunità linguistiche indigene, minoritarie e in via di estinzione stanno adottando ed adattando la tecnologia per aumentare la presenza digitale delle loro lingue. Attraverso questo processo stanno modificando il panorama di internet aumentando la diversità linguistica online. Questa pubblicazione collaborativa verrà compilata da un gruppo di volontari. I collaboratori saranno elencati in fondo a ciascun numero.
Poiché questo è il nostro primo numero, ci aspettiamo che il formato e i contenuti di DigiGlot si evolveranno nei prossimi mesi. Siamo sempre alla ricerca di feedback da parte dei lettori e di suggerimenti riguardo ad argomenti da includere in edizioni future. Potete contattarci tramite la pagina dei contatti [en, come i link seguenti, salvo diversa indicazione] di Rising Voices.
Contents
- 1 Attivismo tecnologico e digitale nel programma per l'Anno Internazionale delle Lingue Indigene
- 2 I caratteri latini “estesi” stanno rallentando la crescita delle pagine africane di Wikipedia?
- 3 Il Selettore Universale della Lingua di Wikipedia aggiunge tre lingue dell'Africa occidentale
- 4 Modernizzare testi in lingua hawaiana premendo un pulsante
- 5 Siri e Alexa parleranno gallese un giorno?
- 6 Le tecnologie di riconoscimento vocale aiutano a documentare la lingua Seneca
- 7 Prossimi eventi & opportunità
Attivismo tecnologico e digitale nel programma per l'Anno Internazionale delle Lingue Indigene
Nel dicembre 2016, l'Assemblea Generale delle Nazioni Unite aveva proclamato il 2019 l’Anno Internazionale delle Lingue Indigene [en, come i link seguenti, salvo diversa indicazione]. Si tratta di una campagna di sensibilizzazione, coordinata dall'UNESCO, che si concentrerà su cinque tematiche tra cui la capacity building [it] (costruzione delle capacità) e l'aumento della cooperazione internazionale. Un consorzio di organizzazioni legate al linguaggio si sta formando per evidenziare la campagna sui social media usando l'hashtag #IYIL2019. Come componente aggiuntivo della campagna, l'UNESCO ha annunciato un bando per l'invio di contributi, indicando “Tecnologia, attivismo digitale e intelligenza artificiale (ad es. tecnologia linguistica)” come uno dei principali temi di interesse.
I caratteri latini “estesi” stanno rallentando la crescita delle pagine africane di Wikipedia?
Uno dei lasciti immediati del colonialismo europeo nell'Africa di oggi è un patchwork disgiunto di sistemi di scrittura per le lingue locali. Anche se molte lingue africane sono state scritte per numerosi decenni usando l'alfabeto latino, le diverse lingue si sono notevolmente diversificate nel loro uso di lettere speciali e accentate, ovvero dei caratteri latini “estesi”. Alcune lingue erano addirittura scritte in modo differente, da un lato all'altro dei confini nazionali. In questa serie di saggi [parti 1, 2, 3], Don Osborn riflette su quattro decenni di standardizzazione della lingua africana, e spiega come le prime decisioni sull'ortografia possano avere avuto conseguenze sulla produzione odierna dei media digitali.
Osborn suggerisce che la sfida presentata dall'utilizzo di ortografie latine estese – quelle che costringono gli utenti a farsi strada attraverso interfacce di input non standardizzate per digitare i caratteri “speciali” nella propria lingua – potrebbe limitare lo sviluppo di alcune Wikipedie africane. La sua analisi rileva che le Wikipedie africane “scritte in un latino esteso e complesso hanno in media circa un terzo del numero di articoli” rispetto a quelle scritte in un alfabeto latino più semplice. Nonostante Osborn riconosca che la sua analisi sia solo preliminare, le sue osservazioni evidenziano utilmente alcune delle complessità della costruzione di ecologie digitali nelle lingue locali.
Il Selettore Universale della Lingua di Wikipedia aggiunge tre lingue dell'Africa occidentale
Ayokunle Odedere è un Wikipediano nigeriano e coordinatore del Wikimedia Hub di Ibadan, in Nigeria. Organizza e mobilita attività e campagne come il recente progetto AfroCine. Lavorando su Wikipedia, Odedere ha notato che sia i redattori nuovi che quelli con esperienza stavano avendo difficoltà a digitare i necessari segni diacritici [it] negli articoli di Wikipedia per le lingue nazionali Yoruba [it], Hausa [it], e Igbo [it].
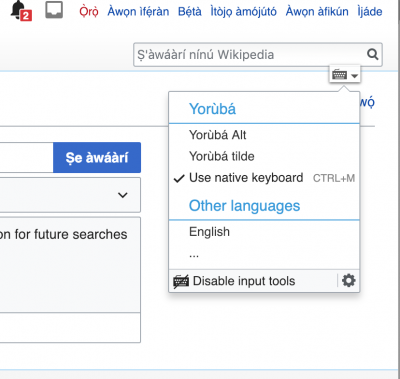 Nonostante ci siano tastiere speciali come le tastiere Yoruba Name per Mac e Windows, e altre tastiere virtuali che consentono agli utenti di visualizzare questi caratteri speciali, queste richiedono un certo grado di conoscenza tecnica per l'installazione e l'utilizzo. Odedere ha immaginato una soluzione integrata nella stessa Wikipedia. Ha inoltrato una richiesta alla Wikimedia Community Wishlist per includere le lingue Yoruba, Hausa e Igbo nel Universal Language Selector (ULS) (Selettore Universale della Lingua), un servizio disponibile per Wikipedia e gli altri progetti Wikimedia per “consentire agli utenti di digitare testo in lingue diverse non direttamente supportate dalla loro tastiera, di leggere il contenuto in uno script per il quale i caratteri non sono disponibili localmente o di personalizzare la lingua in cui vengono visualizzati i menu”. La richiesta è stata accolta e il team di Wikimedia Foundation Language (Fondazione Wikimedia per le Lingue) ha incluso le tre lingue dell'Africa occidentale nell'ULS. Ora gli editor di Wikipedia che usano un computer fisso o un portatile possono incorporare i caratteri speciali nei loro testi digitando il carattere tilde (~) prima della lettera corrispondente.
Nonostante ci siano tastiere speciali come le tastiere Yoruba Name per Mac e Windows, e altre tastiere virtuali che consentono agli utenti di visualizzare questi caratteri speciali, queste richiedono un certo grado di conoscenza tecnica per l'installazione e l'utilizzo. Odedere ha immaginato una soluzione integrata nella stessa Wikipedia. Ha inoltrato una richiesta alla Wikimedia Community Wishlist per includere le lingue Yoruba, Hausa e Igbo nel Universal Language Selector (ULS) (Selettore Universale della Lingua), un servizio disponibile per Wikipedia e gli altri progetti Wikimedia per “consentire agli utenti di digitare testo in lingue diverse non direttamente supportate dalla loro tastiera, di leggere il contenuto in uno script per il quale i caratteri non sono disponibili localmente o di personalizzare la lingua in cui vengono visualizzati i menu”. La richiesta è stata accolta e il team di Wikimedia Foundation Language (Fondazione Wikimedia per le Lingue) ha incluso le tre lingue dell'Africa occidentale nell'ULS. Ora gli editor di Wikipedia che usano un computer fisso o un portatile possono incorporare i caratteri speciali nei loro testi digitando il carattere tilde (~) prima della lettera corrispondente.
Modernizzare testi in lingua hawaiana premendo un pulsante
La lingua hawaiana ha una lunga tradizione di scrittura, con oltre 125.000 pagine di giornale pubblicate nel XIX e all'inizio del XX secolo. Sfortunatamente, la maggior parte di questi testi è stata scritta in un'ortografia ideata da missionari che, a differenza dell'ortografia moderna standard, non riflette pienamente il sistema sonoro della lingua. Ciò comporta che questi vecchi testi sono difficili da leggere per gli oratori di oggi, ed inoltre non possono essere facilmente utilizzati per la formazione di sistemi digitali di elaborazione del linguaggio naturale. Questo documento, redatto da ricercatori dell'Università di Oxford e di Google Deep Mind, descrive un sistema che combina i cosiddetti “trasduttori di stato finito”, una tecnologia ben nota nel settore, con le tecnologie di apprendimento profondo [it] per sviluppare un sistema che modernizzi automaticamente i testi hawaiani. Questo approccio potrebbe essere applicato alle numerose altre lingue che hanno subito modifiche ortografiche o standardizzazione.
Siri e Alexa parleranno gallese un giorno?
Eluned Morgan, ministro della lingua gallese del governo gallese, ha affermato l'importanza di avere altoparlanti intelligenti e dispositivi vocali come Alexa e Siri disponoboli per i parlanti della lingua gallese. Questo obiettivo è parte del Piano d'Azione per la Tecnologia Linguistica Gallese lanciato dal governo, che è stato lanciato il 23 ottobre 2018.
Il piano riconosce il ruolo che la tecnologia gioca nella vita di tutti i giorni e l'importanza per i parlanti gallesi di poter usare la propria lingua quando utilizzano la tecnologia: “Vogliamo che le persone siano in grado di usare facilmente sia gallese che inglese nella loro vita virtuale a casa, a scuola, al lavoro o in movimento”. Il Welsh Technology Language Act (Legge per la Lingua Gallese nella Tecnologia) raccomanda lo sviluppo dell'intelligenza artificiale, in modo che le macchine possano comprendere il gallese parlato e il miglioramento della traduzione assistita da computer, come parte dell'obiettivo più ampio del governo di avere un milione di persone che parlano gallese entro il 2050.
Le tecnologie di riconoscimento vocale aiutano a documentare la lingua Seneca
Un gruppo di ricercatori del Rochester Institute of Technology negli Stati Uniti sta sviluppando una tecnologia di riconoscimento vocale per assistere nella documentazione e nella trascrizione della lingua Seneca. Seneca è una lingua nativo americana a rischio di estinzione parlata correntemente da meno di 50 individui, da questo nasce l'urgenza di documentarla e preservarla. Poiché la registrazione e la trascrizione manuale del discorso parlato sono costose e richiedono molto tempo, i ricercatori stanno cercando di sfruttare la tecnologia di riconoscimento vocale per assistere in questo compito.
Il riconoscimento vocale è un processo tecnologico che riconosce i suoni prodotti dalla voce umana e li trascrive automaticamente in forma scritta. Sviluppare sistemi di riconoscimento vocale per quelle lingue con poche fonti di dati è una sfida, poiché questi sistemi richiedono una grande quantità di dati per “essere addestrati” a riconoscere la lingua. Per questa ricerca all'avanguardia il gruppo ha ricevuto 181.682 dollari distribuiti in quattro anni dalla US National Science Foundation.
Prossimi eventi & opportunità
- L’ Endangered Languages Program (Programma per le Lingue in Via di Estizione) sta collaborando con il Language Documentation Training Center (LDTC) (Centro di Formazione sulla Documentazione Linguistica) per offrire una serie di webinar settimanali gratuiti sulla documentazione linguistica a febbraio e marzo 2019. Gli interessati possono iscriversi utilizzando questo modulo.
- Il bando 2019 del Endangered Language Fund (Fondo per le Lingue in via di Estinzione) per i sussidi del programma Language Legacies (Eredità Linguistiche) è ora aperto. Queste sovvenzioni offrono fino a 4000 dollari (in media circa 2000 dollari) per supportare la documentazione linguistica e gli sforzi di rivitalizzazione in tutto il mondo. Ai potenziali candidati non è richiesta una preparazione accademica. La scadenza per la presentazione delle domande è il 15 marzo 2019.
- PULiiMA 2019 – Indigenous Languages & Technology Conference (Conferenza per le Lingue Indigene e la Tecnologia), che si terrà a Darwin, in Australia, dal 19 al 22 agosto 2019, ha lanciato un bando aperto per presentatori. La scadenza per la presentazione delle domande è il 9 febbraio 2019.

Questo post è ripreso da Rising Voices, progetto del circuito Global Voices mirato a diffondere i citizen media in luoghi dove generalmente la gente non vi ha accesso. · tutti gli articoli





